Computer Vision and Pattern Discovery for Bioimages Group @ BII
-
Novel Multiple Instance Learning Models Exploiting Coarse-level Labels For Fine-level Information
Given some big data and coarse-level labels, extracting fine-level information is a demanding yet rewarding challenge in data science. We developed a novel weakly supervised clustering framework utilizing big data and exploiting coarse-level labels to reveal fine-level details within the data. Given only the weak labels of whether an image contains metastases or not, this framework successfully segmented out breast cancer metastases in the lymph node sections. Our framework was based on the multiple instance learning (MIL) paradigm that learns the mapping between bags of instances and bag labels. One common component in all MIL methods is the MIL pooling filter, which obtains the bag-level representations from extracted features of instances. We introduced distribution-based pooling filters that obtain a bag-level representation by estimating marginal feature distributions. We formally proved that the distribution-based pooling filters are more expressive than the point estimate-based counterparts (like ‘max’ and ‘mean’ pooling) in terms of the amount of information captured while obtaining bag-level representations. Moreover, we empirically showed that models with distribution-based pooling filters perform equal or better than those with point estimate-based pooling filters on distinct real-world MIL tasks. Lastly, we developed a MIL model with a distribution pooling filter predicting tumor purity (percentage of cancer cells within a tissue section) from digital histopathology slides. Our model successfully predicted tumor purity in eight different TCGA cohorts and a local Singapore cohort. The predictions were highly consistent with genomic tumor purity values, which were inferred from genomic data and accepted as accurate for downstream analysis. Furthermore, our model provided tumor purity maps showing the spatial variation of tumor purity within sections, which can help better understand the tumor microenvironment.
Related Publications
-
Mustafa Umit Oner, Hwee Kuan Lee, and Wing-Kin Sung.
Weakly Supervised Clustering by Exploiting Unique Class Count , ICLR 2020.
-
Mustafa Umit Oner, Jared Marc Song Kye-Jet, Hwee Kuan Lee, and Wing-Kin Sung
Studying The Effect of MIL Pooling Filters on MIL Tasks. arXiv preprint arXiv:2006.01561. 2020.
-
Mustafa Umit Oner, Jianbin Chen, Egor Revkov, Anne James, Seow Ye Heng, Arife Neslihan Kaya, Jacob Josiah Santiago Alvarez, Angela Takano, Xin Min Cheng, Tony Kiat Hon Lim, et al.
Obtaining spatially resolved tumor purity maps using deep multiple instance learning in a pan-cancer study Patterns, 3(2):100399. 2022. ( Code )
Malignant Gland Detection in Prostate Core Needle Biopsies
Manual reading of core needle biopsy slides by pathologists is the gold standard for prostate cancer diagnosis. However, it requires the analysis of around 12 (6-18) biopsy cores, including hundreds of glands. It can be a tedious and challenging task to identify the few malignant glands among a large number of benign glands, especially for low-grade, low-volume prostate cancer. These few malignant glands can be easily overlooked, potentially resulting in missed therapeutic opportunities. To assist pathologists, we developed a deep learning-based pipeline to detect malignant glands in core needle biopsy slides of low-grade prostate cancer (Gleason Score 3+3 and 3+4). Our pipeline accepted a whole-slide image of prostate core needle biopsy as input, detected the glands within the slide, and finally classified each gland into benign or malignant. Our novel gland classification model processed multi-resolution patches of each gland and utilized both detailed morphology and neighboring spatial information from high (40x and 20x) and low (10x and 5x) resolution patches, respectively. We tested the pipeline end-to-end on the classification of tissue parts in core needle biopsies. The pipeline successfully classified the tissue parts (81 parts: 50 benign and 31 malignant), and an AUROC value of 0.997 (95% CI: 0.987 - 1.000) was obtained.
Related Publications
-
Mustafa Umit Oner*, Mei Ying Ng*, Danilo Medina Giron, Cecilia Ee Chen Xi, Louis Ang Yuan Xiang, Malay Singh, Weimiao Yu, Wing-Kin Sung, Chin Fong Wong, and Hwee Kuan Lee.
An AI-assisted Tool For Efficient Prostate Cancer Diagnosis in Low-grade and Low-volume Cases. , Patterns 4, 100642. 2022. *Equal contribution.
Weakly Supervised Clustering by Exploiting Unique Class Count
A weakly supervised learning based clustering framework is proposed in this paper. As the core of this framework, we introduce a novel multiple instance learning task based on a bag level label called unique class count (ucc), which is the number of unique classes among all instances inside the bag. In this task, no annotations on individual instances inside the bag are needed during training of the models. We mathematically prove that with a perfect ucc classifier, perfect clustering of individual instances inside the bags is possible even when no annotations on individual instances are given during training. We have constructed a neural network based ucc classifier and experimentally shown that the clustering performance of our framework with our weakly supervised ucc classifier is comparable to that of fully supervised learning models where labels for all instances are known. Furthermore, we have tested the applicability of our framework to a real world task of semantic segmentation of breast cancer metastases in histological lymph node sections and shown that the performance of our weakly supervised framework is comparable to the performance of a fully supervised Unet model.
Related Publications
-
Mustafa Umit Oner, Hwee Kuan Lee, and Wing-Kin Sung.
Weakly Supervised Clustering by Exploiting Unique Class Count , ICLR 2020.
Fence GAN: Towards Better Anomaly Detection.
Anomaly detection is a classical problem where the aim is to detect anomalous data that do not belong to the normal data distribution. Current state-of-the-art methods for anomaly detection on complex high-dimensional data are based on the generative adversarial network (GAN). However, the traditional GAN loss is not directly aligned with the anomaly detection objective: it encourages the distribution of the generated samples to overlap with the real data and so the resulting discriminator is ineffective as an anomaly detector. In this paper, we propose modifications to the GAN loss such that the generated samples lie at the boundaries of the real data distribution. With our modified GAN loss, our anomaly detection method, called Fence GAN (FGAN), directly uses the discriminator score as an anomaly threshold. Our experimental results on the MNIST, CIFAR10 and KDD99 datasets show that FGAN yields the best anomaly classification accuracy compared to state-of-the-art methods.
Related Publications
-
Phuc Cuong Ngo et al
Fence GAN: Towards Better Anomaly Detection. International Conference on Tools with Artificial Intelligence (ICTAI) 2019.
Enhancing Transformation-Based Defenses Against Adversarial Attacks with a Distribution Classifier
Adversarial attacks on convolutional neural networks (CNN) have gained significant attention and there have been active research efforts on defense mechanisms. Stochastic input transformation methods have been proposed, where the idea is to recover the image from adversarial attack by random transformation, and to take the majority vote as consensus among the random samples. However, the transformation improves the accuracy on adversarial images at the expense of the accuracy on clean images. While it is intuitive that the accuracy on clean images would deteriorate, the exact mechanism in which how this occurs is unclear. In this paper, we study the distribution of softmax induced by stochastic transformations. We observe that with random transformations on the clean images, although the mass of the softmax distribution could shift to the wrong class, the resulting distribution of softmax could be used to correct the prediction. Furthermore, on the adversarial counterparts, with the image transformation, the resulting shapes of the distribution of softmax are similar to the distributions from the clean images. With these observations, we propose a method to improve existing transformation-based defenses. We train a separate lightweight distribution classifier to recognize distinct features in the distributions of softmax outputs of transformed images. Our empirical studies show that our distribution classifier, by training on distributions obtained from clean images only, outperforms majority voting for both clean and adversarial images. Our method is generic and can be integrated with existing transformation-based defenses
Related Publications
-
Connie (Khor Li) Kou et al
Enhancing Transformation-Based Defenses Against Adversarial Attacks with a Distribution Classifier ICLR2020
Assessing Coronary Artery Disease from Angiography Video Sequences
Coronary angiography is the gold standard imaging technique for visualizing the coronary arteries which aids in diagnosing coronary artery disease, and guiding patient management. Iodine-based contrast is injected into the coronary arteries and multiple moving X-ray images are acquired from different view angles around the patient torso. Cardiologists are trained to interpret the coronary angiogram, but this takes time and there may be interobserver disagreement. In a new collaboration with the National Heart Centre Singapore, we are exploring artificial intelligence approaches to analyzing X-ray video sequences with the goal of developing a quantitative assessment tool for repeatable and objective angiographic measurements.
Related Publications
-
Chengyang Zhou, Thao Vy Dinh, Heyi Kong, Jonathan Yap, Khung Keong Yeo, Hwee Kuan Lee, Kaicheng Liang
Automated Deep Learning Analysis of Angiography Video Sequences for Coronary Artery Disease (2021), arXiv
AI driven national Platform for CT cOronary angiography for clinicaL and industriaL applicatiOns (APOLLO)
Coronary artery disease (CAD), a blockage of the blood vessels, affects 6% of the general population and up to 20% of those over 65 years of age. CAD is a leading cause of cardiac mortality in Singapore and worldwide, with 19% of deaths in Singapore due to CAD (MOH website). Numbers of CAD cases are growing rapidly due to ageing and higher prevalence of diabetes. Computed Tomography Coronary Angiography (CTCA) is the first-line investigator for CAD as indicated by updated National Institute for Clinical Excellence (NICE) guidelines. Recent Prospective Multicenter Imaging Study for Evaluation of Chest Pain (PROMISE) and Scottish Computed Tomography of the Heart (SCOT-HEART) trials support CTCA as the dominant means for evaluating coronary anatomy and physiology because CTCA increases diagnostic certainty, improves efficiency of triage to invasive catheterization and reduces radiation exposure when compared with functional stress testing. Current practice of CAD report generation requires 3-6 hours of a CT specialist’s time for annotating the scans, and with inter-observer variability of 20%. In addition, there is no effective toolkit to analyse Agatston scores (a measure of calcified CAD), severity of stenosis, and plaque characterisation. These problems have strongly and severely constrained the effectiveness of CTCA as a diagnostic and research tool. We plan to build upon Singapore’s competitive advantages in artificial intelligence (AI) to provide a solution to these gaps. Our overall aim is to build an AI-driven CT Coronary Angiography platform for automated anonymization, reporting, Agatston scoring and plaque quantification in CAD. It is a “one-stop” platform spanning from diagnosis to clinical, management and prognosis, and aid in predicting therapy response in the pharmaceutical industries.
Explaining Adversarial Vulnerability with a Data Sparsity Hypothesis
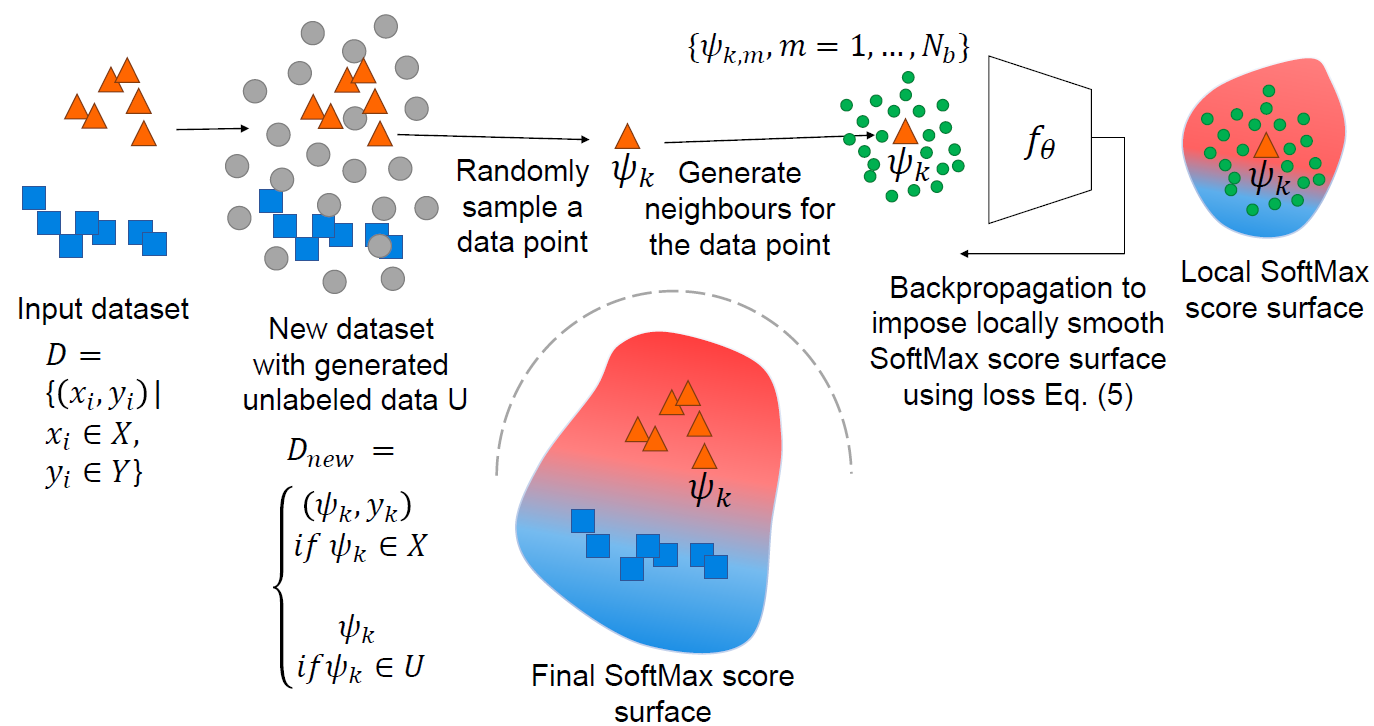
Despite many proposed algorithms to provide robustness to deep learning (DL) models, DL models remain susceptible to adversarial attacks. We hypothesize that the adversarial vulnerability of DL models stems from two factors. The first factor is data sparsity which is that in the high dimensional input data space, there exist large regions outside the support of the data distribution. The second factor is the existence of many redundant parameters in the DL models. Owing to these factors, different models are able to come up with different decision boundaries with comparably high prediction accuracy. The appearance of the decision boundaries in the space outside the support of the data distribution does not affect the prediction accuracy of the model. However, it makes an important difference in the adversarial robustness of the model. We hypothesize that the ideal decision boundary is as far as possible from the support of the class distributions. In this project, we develop a training framework to observe if DL models are able to learn such a decision boundary spanning the space around the class distributions further from the data points themselves. Figure shows the pipeline for training such a DL model for the labeled dataset shown on the left with two class distributions (Circle and Square). For this training dataset an unlabeled dataset is generated to cover a large area around the labeled dataset in the high dimensiontal input data space. During training a data point is sampled from either the labeled or unlabeled dataset. The local SoftMax score surface around the sampled data point and the generated neighbors for that data point is made smooth using a regularizer. The final SoftMax score surface of the model for the labeled dataset is shown at the bottom of the figure. This SoftMax score surface is smooth and it's decision boundary stays away from the support of the class distributions in the input dataset.
Related Publications
-
Mahsa Paknezhad, Cuong Phuc Ngo, Amadeus Aristo Winarto, Alistair Cheong, Beh Chuen Yang, Wu Jiayang, Lee Hwee Kuan
Explaining Adversarial Vulnerability with a Data Sparsity Hypothesis (2022), Neurocomputing.
-
Mustafa Umit Oner, Hwee Kuan Lee, and Wing-Kin Sung.