Method
In this work, we aim to learn a direct mapping from a segmentation back to the raw filamentary strcutured image. The pipline of our method is shown in Figure. 1(a). There are three components in our approach: a generator, a discriminator, and a feature network which is only for the Fila-sGAN variant, with detailed information shown in Figure. 1(b), Figure. 1(c), and Figure. 1(d), respectively. The first two components form our base approach, Fila-GAN, while our Fila-sGAN variant also contains this addtional feature network component. The generator takes segmentation map and noise vector as input and produce color images (the raw filamentary strcutured image), while the discriminator is to identify the real images from the fake ones (i.e. the generated phantoms).
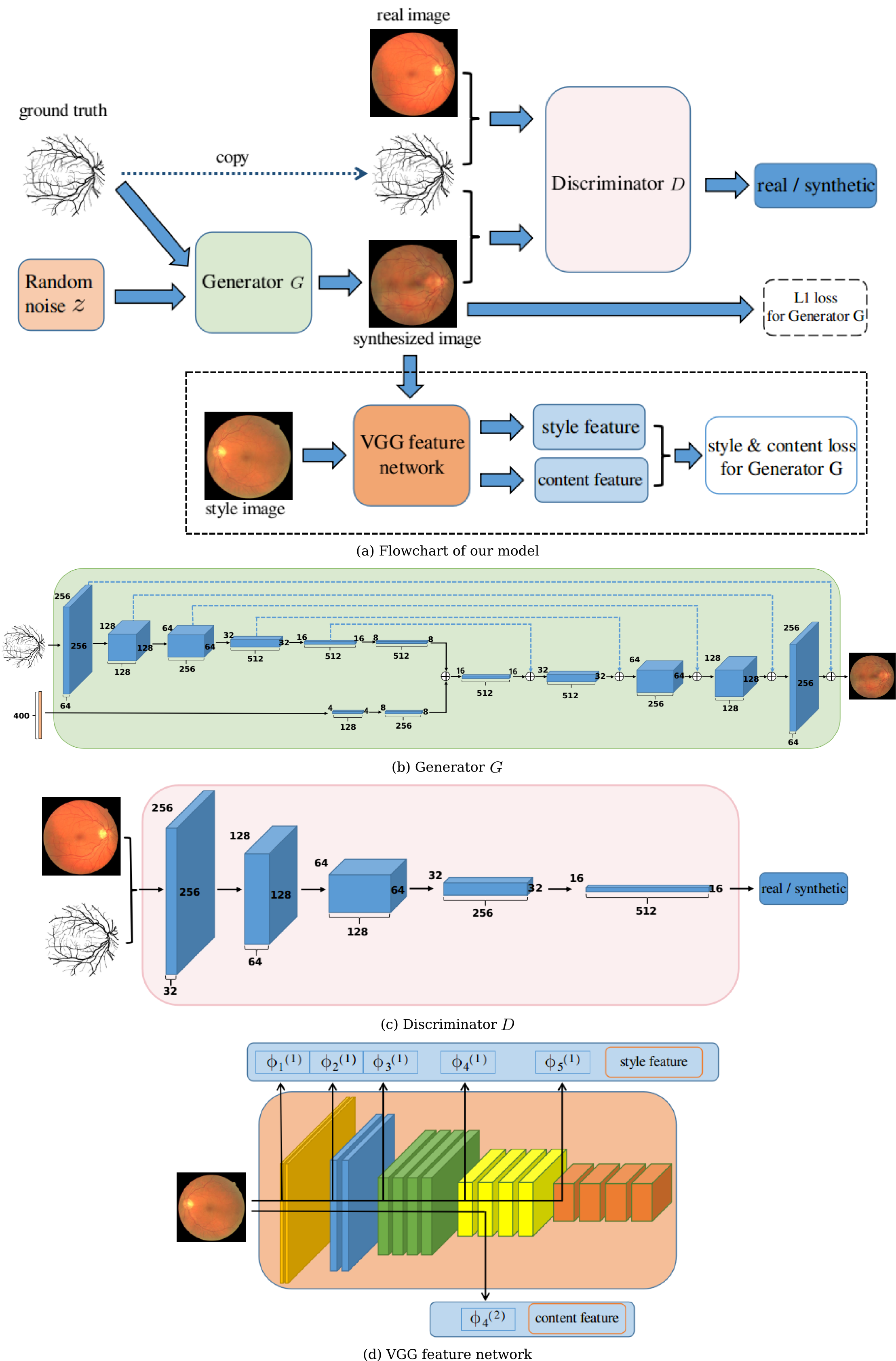
Fig. 1 (a) Flowchart of our approach, which contains the generator and the discriminator networks as detailed in (b) and (c). The dimensions of all layers are specified. The VGG feature networks are described in (d), where the top row indicates the sepcific layers extracted as style feature, while bottom row are the layers used as content features.